3.2 理解线程束执行的本质01
【CUDA 基础】3.2 理解线程束执行的本质(Part I)
2018-03-14 | CUDA , Freshman | 0 |
Abstract: 本文介绍CUDA执行模型最核心的部分,线程束的执行实质第一部分 Keywords: CUDA分支,线程束分化
理解线程束执行的本质(Part I)
我们前面已经介绍了CUDA执行模型的大概过程,包括线程网格、线程束、线程间的关系,以及硬件的大概结构,例如SM的大概结构。而对于硬件来说,CUDA执行的实质是线程束的执行,因为硬件根本不知道每个块谁是谁,也不知道先后顺序,硬件(SM)只知道按照机器码运行,而给它什么、先后顺序,这个就是硬件功能设计的直接体现了。
从外表来看,CUDA执行所有的线程,并行的,没有先后顺序的,但实际上硬件资源是有限的,不可能同时执行百万个线程,所以从硬件角度来看,物理层面上执行的也只是线程的一部分,而每次执行的这一部分,就是我们前面提到的线程束。
线程束和线程块
线程束是SM中基本的执行单元。当一个网格被启动(网格被启动,等价于一个内核被启动,每个内核对应于自己的网格),网格中包含线程块,线程块被分配到某一个SM上以后,将分为多个线程束,每个线程束一般是32个��线程(目前的GPU都是32个线程,但不保证未来还是32个)。在一个线程束中,所有线程按照单指令多线程SIMT的方式执行,每一步执行相同的指令,但是处理的数据为私有的数据。下图反映的就是逻辑、实际和硬件的图形化。
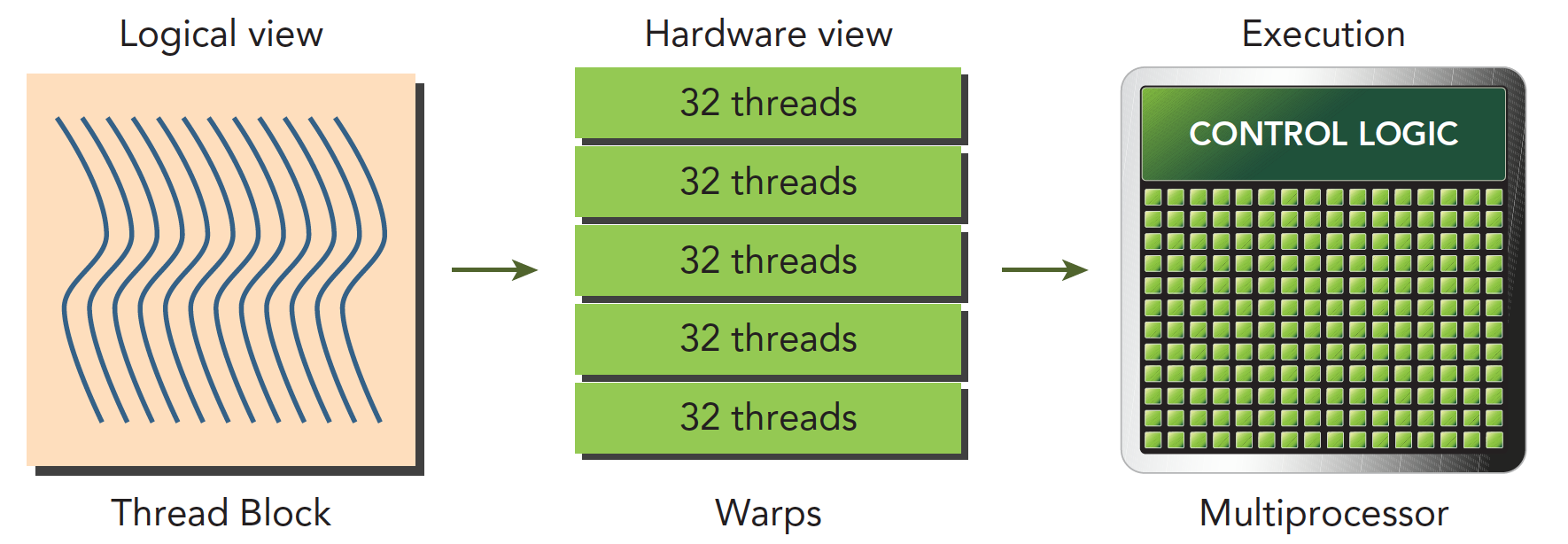
线程块是个逻辑产物,因为在计算机里,内存总是一维线性存在的,所以执行起来也是一维的访问线程块中的线程,但是我们在写程序的时候却可以以二维三维的方式进行,原因是方便我们写程序,比如处理图像或者三维的数据,三维块就会变得很直接、很方便。
在块中,每个线程有唯一的编号(可能是个三维的编号),threadIdx。 网格中,每个线程块也有唯一的编号(可能是个三维的编号),blockIdx。 那么每个线程就有在网格中的唯一编号。
当一个线程块中有128个线程的时候,其分配到SM上执行时,会分成4个线程束:
warp0: thread 0,........thread31
warp1: thread 32,........thread63
warp2: thread 64,........thread95
warp3: thread 96,........thread127
当编号使用三维编号时,x位于最内��层,y位于中层,z位于最外层,想象下C语言的数组,如果把上面这句话写成C语言,假设三维数组t保存了所有的线程,那么(threadIdx.x,threadIdx.y,threadIdx.z)表示为:
t[z][y][x];
计算出三维对应的线性地址是:
tid = threadIdx.x + threadIdx.y × blockDim.x + threadIdx.z × blockDim.x × blockDim.y
上面的公式可以借助C语言的三维数组计算相对地址的方法,如果有人做过图像或者矩阵,那么这个计算过程应该没什么纠结的。但是对于初学者,这个地方经常性地绕晕,就像我刚开始写图像算法的时候��,经常搞不清楚长和宽。
一个线程块包含多少个线程束呢?
WarpsPerBlock = ceil(ThreadsPerBlock/warpSize)
ceil函数是向正无穷取整的函数,比如ceil(1.98) = 2。
线程束和线程块,一个是硬件层面的线程集合,一个是逻辑层面的线程集合,我们编程时为了程序正确,必须从逻辑层面计算清楚,但是为了得到更快的程序,硬件层面是我们应该注意的。
线程束分化
线程束被执行的时候会被分配给相同的指令,处理各自私有的数据,还记得前文中的分苹果吗?每次分的水果都是一样的,但是你可以选择吃或者不吃,这个吃和不吃就是分支。在CUDA中支持C语言的控制流,比如if…else, for ,while等,CUDA中同样支持,但是如果一个线程束中的不同线程包含不同的控制条件,那么当我们执行到这个控制条件时就会面临不同的选择。
这里要讲一下CPU了,当我们的程序包含大量的分支判断时,从程序角度来说,程序的逻辑是很复杂的,因为一个分支就会有两条路可以走,如果有10个分支,那么一共有1024条路走。CPU采用流水线化作业,如果每次等到分支执行完再执行下面的指令会造成很大的延迟,所以现在处理器都采用分支预测技术,而CPU的这项技��术相对于GPU来说高级了不止一点点,而这也是GPU与CPU的不同,设计初衷就是为了解决不同的问题。CPU适合逻辑复杂计算量不大的程序,比如操作系统、控制系统,GPU适合大量计算简单逻辑的任务,所以被用来计算。
如下一段代码:
if (condition)
{
// do something
}
else
{
// do something
}
假设这段代码是核函数的一部分,那么当一个线程束的32个线程执行这段代码的时候,如果其中16个执行if中的代码段,而另外16个执行else中的代码块,同一个线程束中的线程,执行不同的指令,这叫做线程束的分化。
我们知道在每个指令周期,线程束中的所有线程执行相同的指令,但是线程束又是分化的,所以这似乎是相悖的,但是事实上这两个可以不矛盾。
解决矛盾的办法就是每个线程都执行所有的if和else部分,当一部分condition成立的时候,执行if块内的代码,有一部分线程condition不成立,那么它们怎么办?继续执行else?不可能的,因为分配命令的调度器就一个,所以这些condition不成立的线程等待,就像分水果,你不爱吃,那你就只能看着别人吃,等大家都吃完了,再进行下一轮(也就是下一个指令)。线程束分化会产生严重的性能下降。条件分支越多,并行性削弱越严重。
注意线程束分化研究的是一个线程束中的线程,不同线程束中的分支互不影响。
执行过程如下:
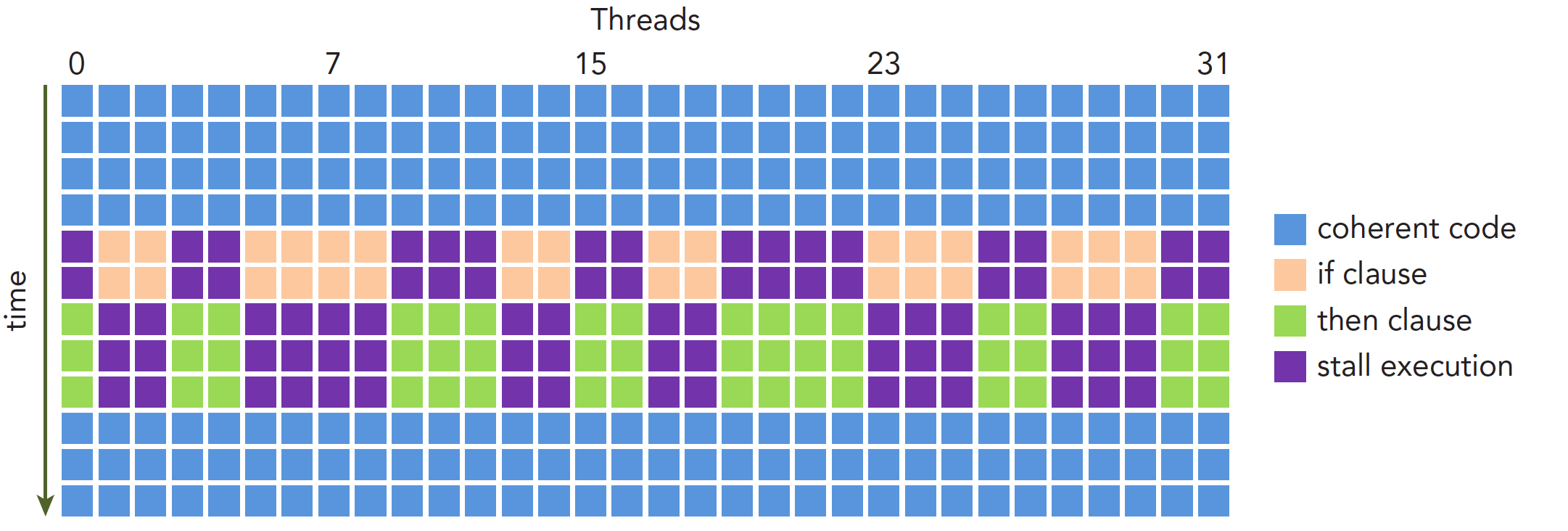
因为线程束分化导致的性能下降就应该用线程束的方法解决,根本思路是避免同一个线程束内的线程分化,而让我们能控制线程束内线程行为的原因是线程块中线程分配到线程束是有规律的而不是随机的。这就使得我们根据线程编号来设计分支是可行的。补充说明下,当一个线程束中所有的线程都执行if或者都执行else时,不存在性能下降;只有当线程束内有分歧产生分支的时候,性能才会急剧下降。
线程束内的线程是可以被我们控制的,那么我们就把都执行if的线程塞到一个线程束中,或者让一个线程束中的线程都执行if,另外线程都执行else的这种方式可以将效率提高很多。
下面这个kernel可以产生一个比较低效的分支:
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if (tid % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
这种情况下我们假设只配置一个x=64的一维线程块,那么只有两个线程束,线程束内奇数线程(threadIdx.x为奇数)会执行else,偶数线程执行if,分化很严重。
但是如果我们换一种方法,得到相同但是错乱的结果C,这个顺序其实是无所谓的,因为我们可以后期调整。那么下面代码就会很高效:
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize) % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
第一个线程束内的线程编号tid从0到31,tid/warpSize都等于0,那么就都执行if语句。 第二个线程束内的线程编号tid从32到63,tid/warpSize都等于1,执行else。 线程束内没有分支,效率较高。
完整代码:https://github.com/Tony-Tan/CUDA_Freshman
#include <cuda_runtime.h>
#include <stdio.h>
#include <stdlib.h>
#include "freshman.h"
__global__ void warmup(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize) % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
// printf("%d %d %f \n",tid,warpSize,a+b);
c[tid] = a + b;
}
__global__ void mathKernel1(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if (tid % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
__global__ void mathKernel2(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
if ((tid/warpSize) % 2 == 0)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
__global__ void mathKernel3(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
bool ipred = (tid % 2 == 0);
if (ipred)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
int main(int argc, char **argv)
{
int dev = 0;
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("%s using Device %d: %s\n", argv[0], dev, deviceProp.name);
// set up data size
int size = 64;
int blocksize = 64;
if (argc > 1) blocksize = atoi(argv[1]);
if (argc > 2) size = atoi(argv[2]);
printf("Data size %d ", size);
// set up execution configuration
dim3 block(blocksize,1);
dim3 grid((size - 1) / block.x + 1,1);
printf("Execution Configure (block %d grid %d)\n", block.x, grid.x);
// allocate gpu memory
float * C_dev;
size_t nBytes = size * sizeof(float);
float * C_host = (float*)malloc(nBytes);
cudaMalloc((float**)&C_dev, nBytes);
// run a warmup kernel to remove overhead
double iStart, iElaps;
cudaDeviceSynchronize();
iStart = cpuSecond();
warmup<<<grid,block>>>(C_dev);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("warmup\t <<<%d,%d>>>elapsed %lf sec \n", grid.x, block.x, iElaps);
// run kernel 1
iStart = cpuSecond();
mathKernel1<<<grid,block>>>(C_dev);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("mathKernel1<<<%4d,%4d>>>elapsed %lf sec \n", grid.x, block.x, iElaps);
cudaMemcpy(C_host,C_dev,nBytes,cudaMemcpyDeviceToHost);
/*
for(int i=0;i<size;i++)
{
printf("%f ",C_host[i]);
}
*/
// run kernel 2
iStart = cpuSecond();
mathKernel2<<<grid,block>>>(C_dev);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("mathKernel2<<<%4d,%4d>>>elapsed %lf sec \n", grid.x, block.x, iElaps);
// run kernel 3
iStart = cpuSecond();
mathKernel3<<<grid,block>>>(C_dev);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("mathKernel3<<<%4d,%4d>>>elapsed %lf sec \n", grid.x, block.x, iElaps);
cudaFree(C_dev);
free(C_host);
cudaDeviceReset();
return EXIT_SUCCESS;
}
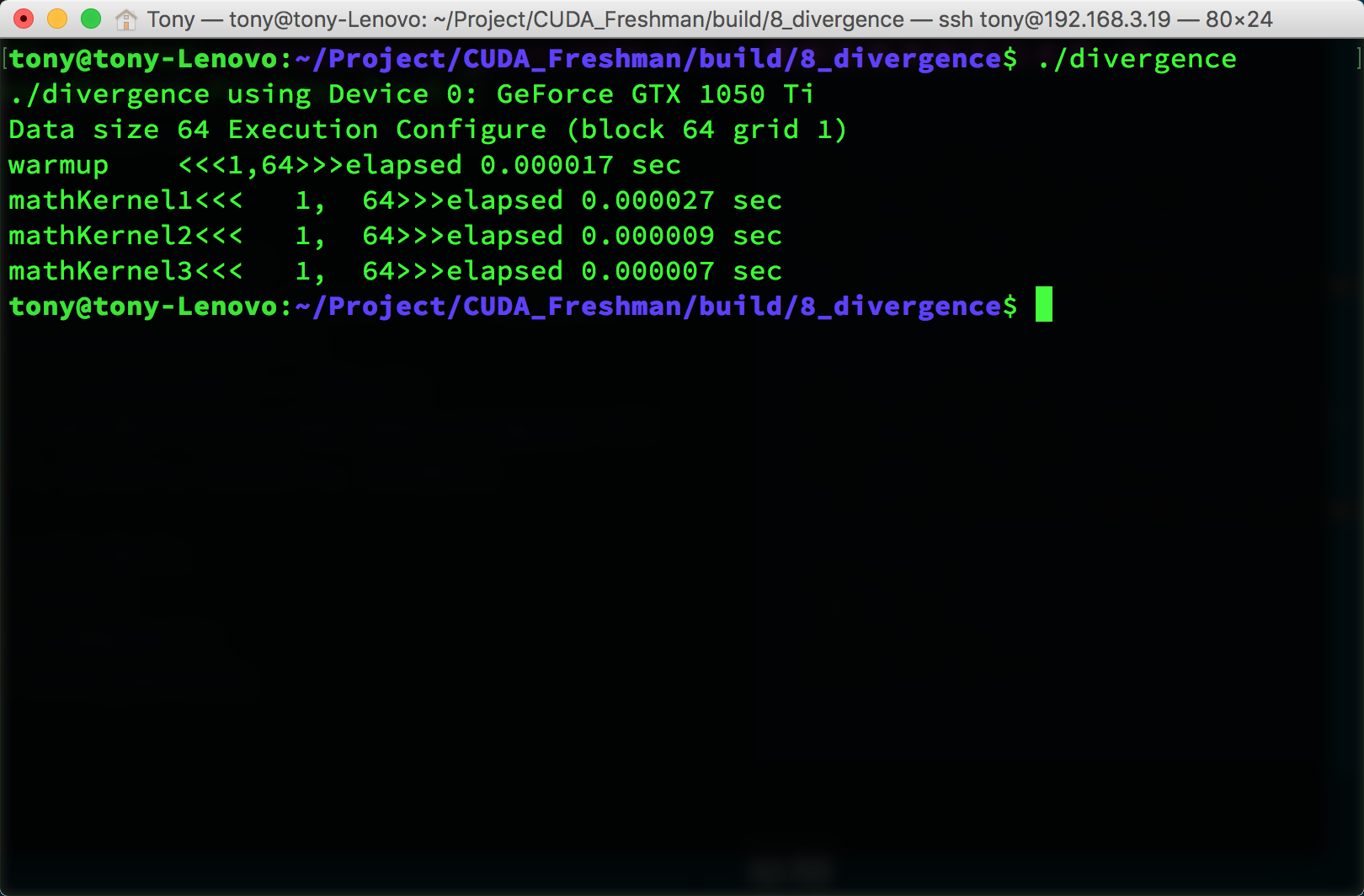
代码中warmup部分是提前启动一次GPU,因为第一次启动GPU时会比第二次速度慢一些,具体原因未知,可以去查一下CUDA的相关技术文档了解内容。我们可以通过nvprof分析一下程序执行过程:
nvprof --metrics branch_efficiency ./divergence
然后得到下面这些参数:
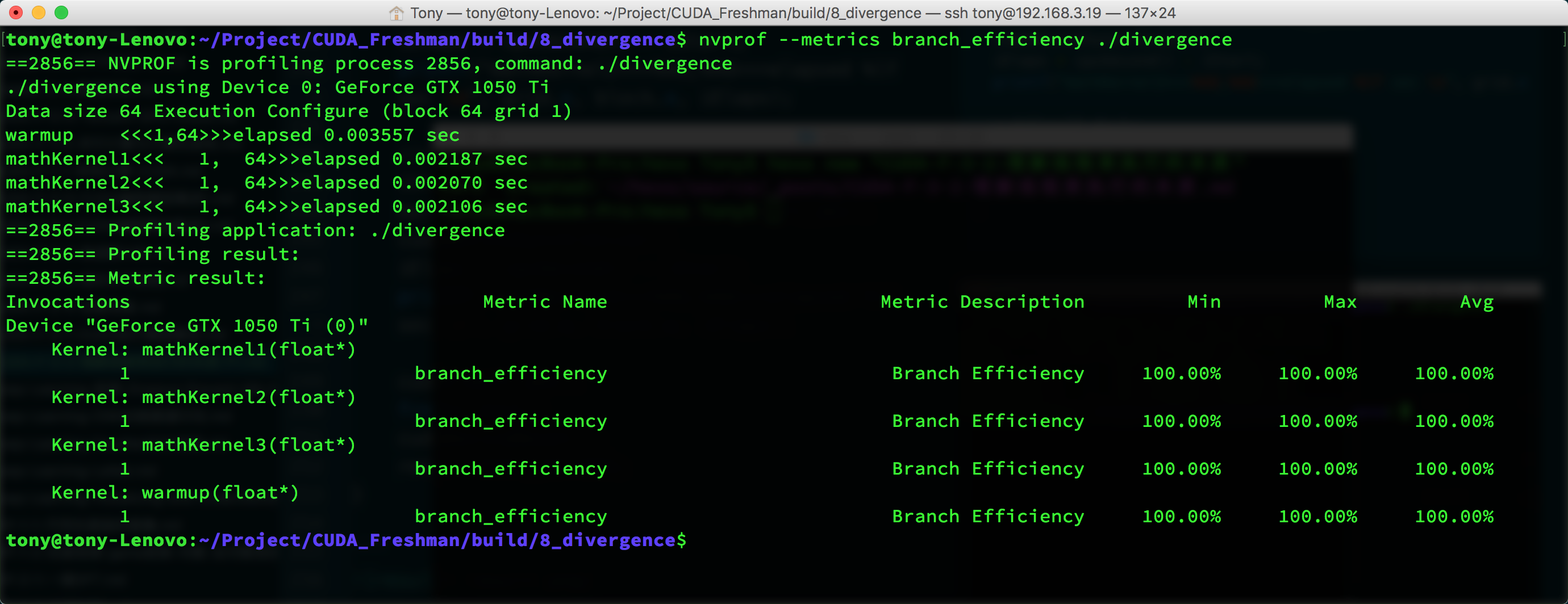
可以看到这里面所有kernel的分支效率都是100%,而这个值的计算是这样的:
Branch Efficiency = (Branches - DivergentBranches) / Branches
但是这又有问题了,明明我们kernel1的分支效率应该是50%,但是为什么测试结果是100%呢?
因为编译器帮我们进行了优化,这个具体原因我们不在Freshman系列中介绍了,下一系列我们会深入进行,所以这里先挖个坑。
但是下面我们用另一种方式,编译器就不会优化了:
// kernel 3
__global__ void mathKernel3(float *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x;
float a = 0.0;
float b = 0.0;
bool ipred = (tid % 2 == 0);
if (ipred)
{
a = 100.0f;
}
else
{
b = 200.0f;
}
c[tid] = a + b;
}
执行结果还是上面那张图,那里面已经有kernel3了。我们也可以通过编译选项禁用分支预测功能,这样kernel1和kernel3的效率是相近的。如果使用nvprof,会得到下面的结果,没有优化的结果如下:
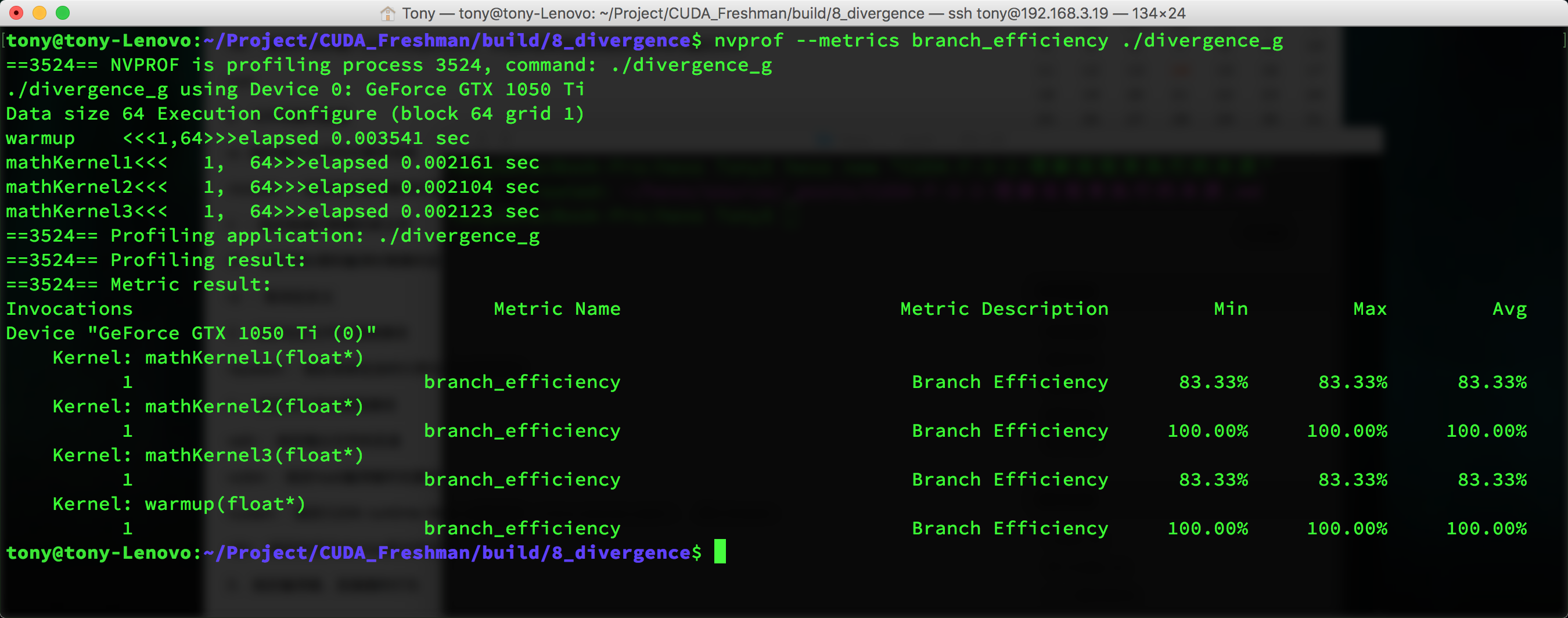
和我们预测的结果基本一致。
我们考察一下事件计数器:
nvprof --events branch,divergent_branch ./divergence_g
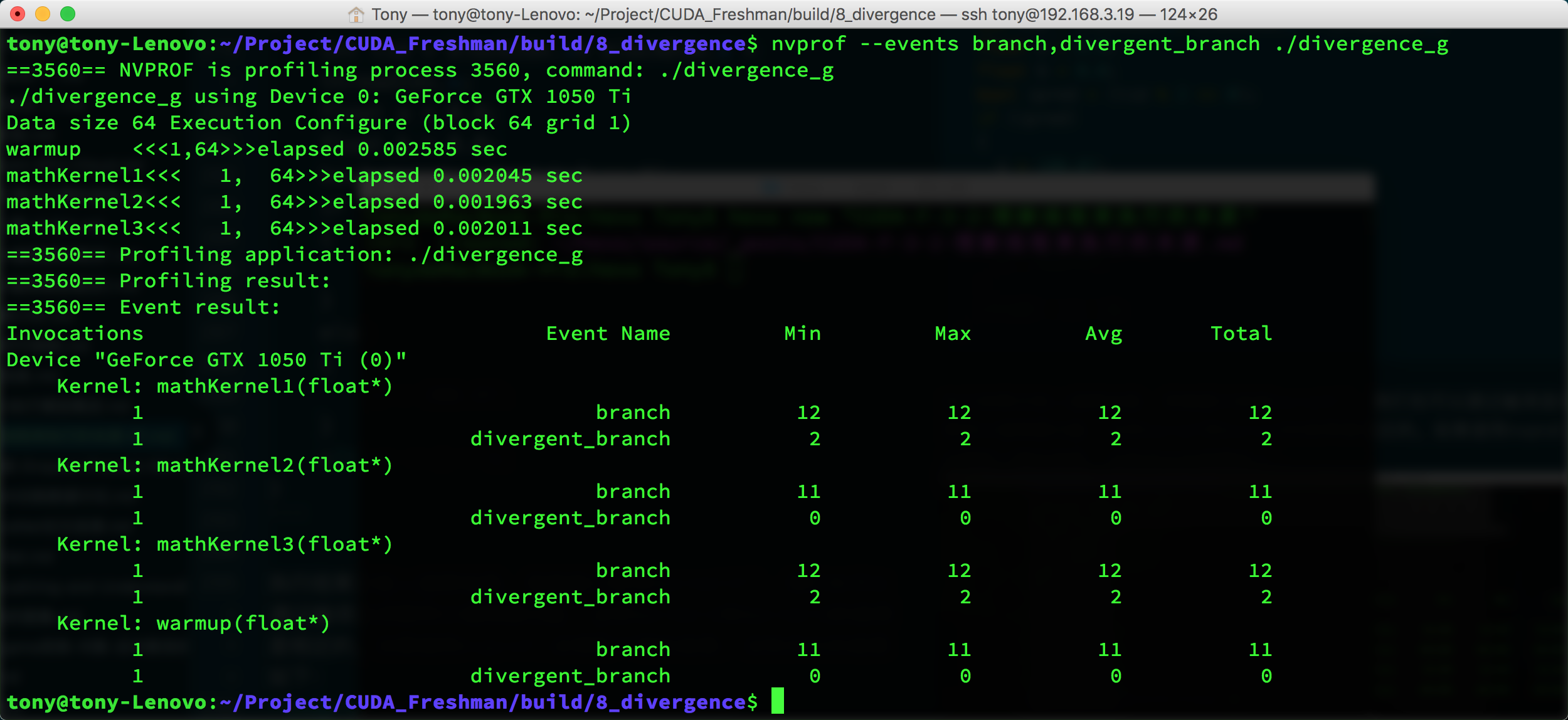
nvcc在1和3上优化有限,但是也超过了50%以上的利用率。
事件和指标
上面我们提到了事件event,事件是可计算的活动,比如这个分支就是一个可以计算的活动,对应一个在内核执行期间被收集的硬件计数器。
指标是内核的特征,由一个或多个事件计算得到。
总结
总结,我们今天介绍了分支的一部分,后面的部分我们下一篇继续。